Moving from Arduino to ARM
Moving from Arduino to ARM can be quite intimidating! This post looks at IDEs from different vendors and weighs the benefits and cost of each IDE for a beginner.


Moving from Arduino to ARM can be a frightening thing! The IDEs out there are more often intimidating because they bristle with features. For someone coming from Arduino where there was only really five buttons you could press in the IDE, this change is somewhat like moving from a car to an airplane.
Atmel
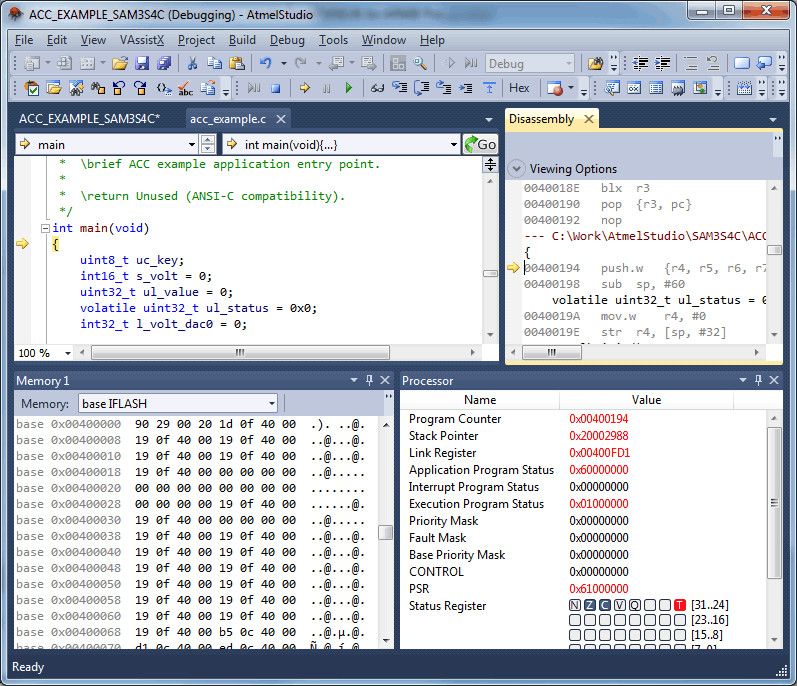
I first tried Atmel Studio because they are closely linked to Arduino, but the only other time I've had occasion to use it was to upload Arduino bootloader code onto SAMD21 chips.
The ASF explorer is Atmel Studio's wunderkind for code examples, and often just examining the code or stright up copying and pasting, a-la "How do I do [insert action]" on Google and reading the first StackExchange example for Arduino. Just about every example you could think of is here and directly searchable.
While this is a wonderful tool and there are a million examples written for it, coming in as a self-taught beginner was incredibly intidimdating because it was mostly in crytic #define PLL_TIMERs. A lot of this code is hidden from you in Arduino, and not necessarily a bad thing I'd say. However, considering how cluttered the interface is on Atmel Studio, it can be very intimidating for a newcomer wanting to program their first Blink program.
ST

ST produces extremely cheap ARM cores, and even better, they provide very affordable dev boards. The STM32 line has been extensively copied by chinese manufacturers, giving rise to copycats and ultra cheap dev boards. Getting started can be as easy as picking up one of their Nucleo lines, which are dev boards that have been designed for mbed, an online IDE that pulls together many boards under one flag. Write code, compile in the cloud, download it to your device. No fiddling around with toolchains.
I like the online IDE, mbed, although it is still hard to know what actions are possible and how the pins are defined for each board. There is also the issue of working online, which I am slightly leery about, because even though I have a good internet connection, I don't want to necessarily depend on it to compile my code. In fact, the few critical moments where I had to compile code was when I didn't have Internet access.
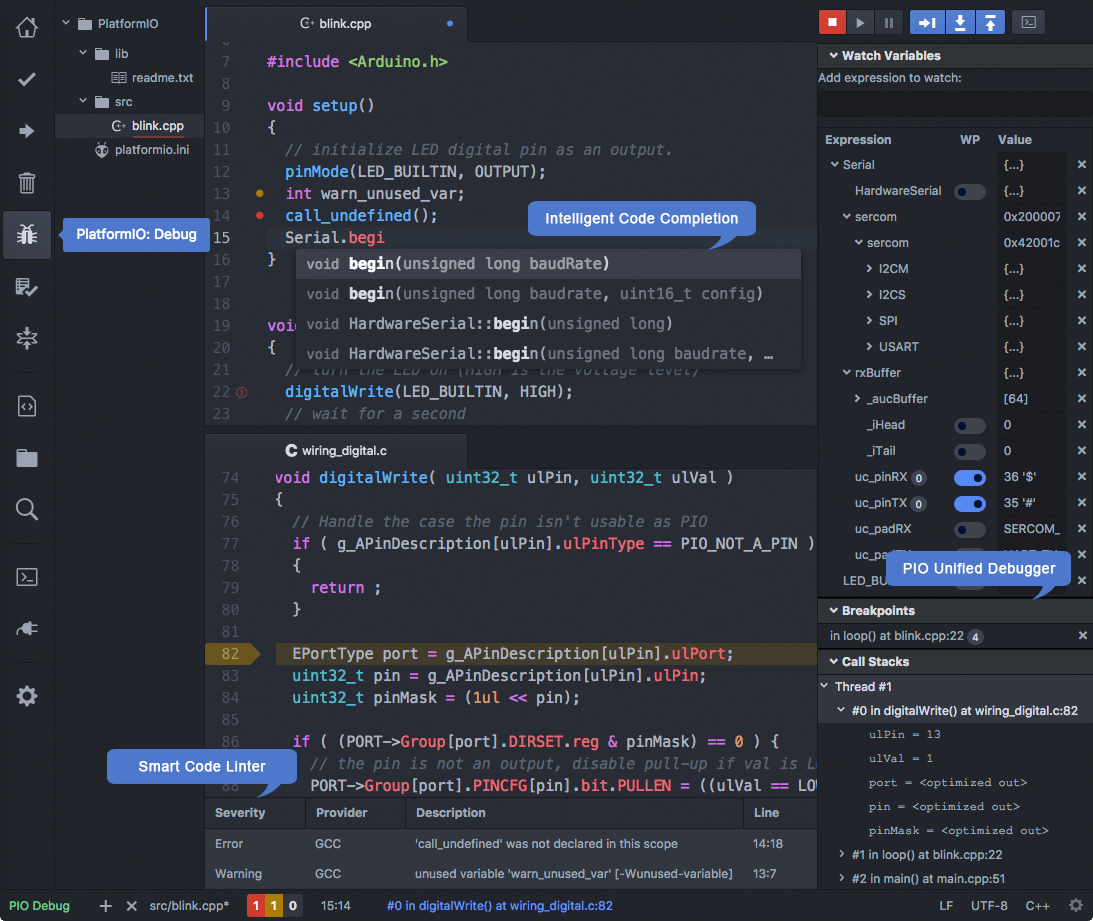
Setting up the development environment for the STM32 offline can range from challenging to difficult. If you want to set up a more traditional environment, the process can become pretty complex. There are many packages that ST has developed that works with other commercial IDEs such as IAR and Keil, both of which are paid options, and AC6, a free eclipse-based IDE.
If you like mbed and want to take it offline, PlatformIO is an offline option, which is a simplified interface to embedded development, overlaid over other IDEs like the Atom or Microsoft Visual Studio Code. It took a few steps to set up the environment, and barring one initial bug in VS Code where I had to use the command line to upload the code the first time, it generally worked well and smoothly. It is also less cumbersome than the mbed drag-and-drop method. It is also significantly less cluttered than Atmel Studio.
TI
Texas Instruments does not only manufacture overpriced graphical calculators, it also makes microcontrollers. TI makes microcontrollers that can be twice as expensive as similar microcontrollers to its competitors. Where it really shines however, is how programming is structured. Instead of leaving it all for the user to figure it out themselves or selling an expensive IDE, TI has instead produced a very structured IDE that installs in one click. Just download the Code Composer Studio (CCS) from TI and install it, and you will have access to all boards with everything necessary already in place.
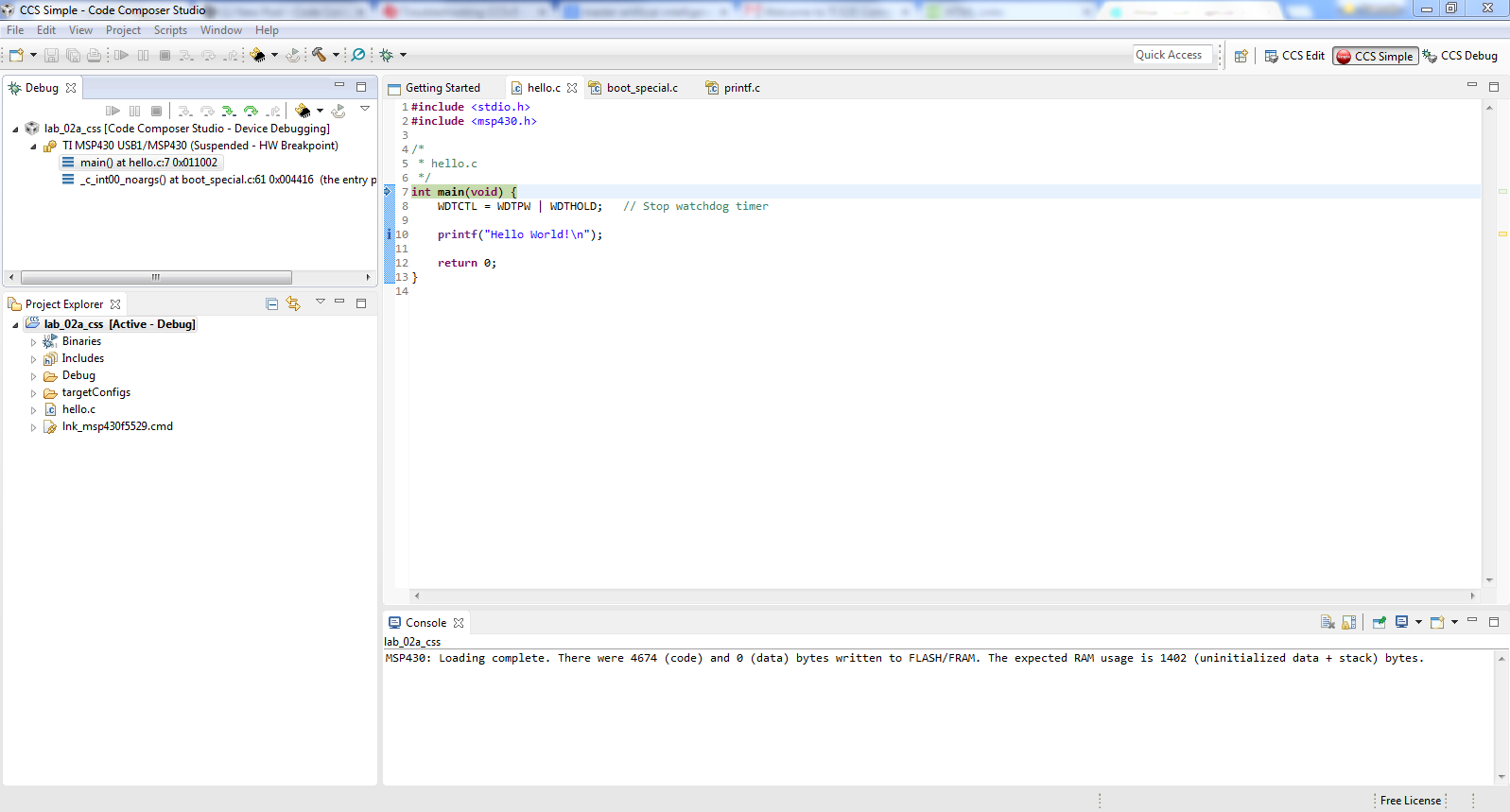
One very important point I would like to stress is that it has a Simple Mode option when opening the CCS which hides most options, only leaving the most important ones behind. This creates a very clean interface, but it is also different from Arduino in that it uses the Eclipse IDE as its backbone. This provides a very easy transition from Arduino into something more complex without too much puzzling. I really like this way of introducing IDEs as the complexity can scale with me instead of having to wade through massive amounts of buttons and menus just to compile and upload my code, as I become more competent, I can enable more of the IDEs functions.
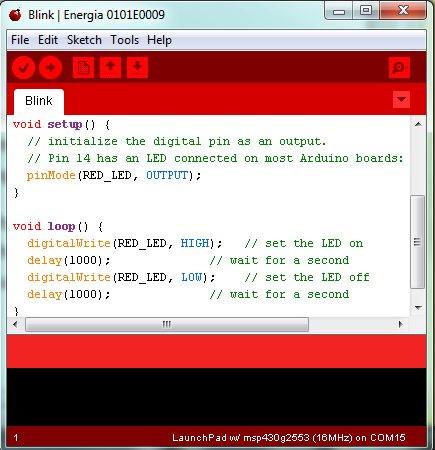
What is even more amazing is that TI provides it's own Arduino spin-off in the form of Energia, which offers the same Arduino interface in TI red. Energia sketches can be imported into CCS, which provides a seamless interface to move from Arduino into a more complex programming environment.
For a beginner, it seems like moving into TI as a basis to upgrade my embedded skills is the best option. Jay Carlson (author of The Amazing $1 Microcontroller seems to agree too!
One drawback is that TI tends to be more expensive especially at the value end of their microcontroller line. However, once you hit Cortex M4Fs, the prices tend to be about the same.